RELEASE NOTES
October release
We are pleased to present you the newest Metamaze features.
Do you have questions? You can always reach out to support@metamaze.eu.
New features
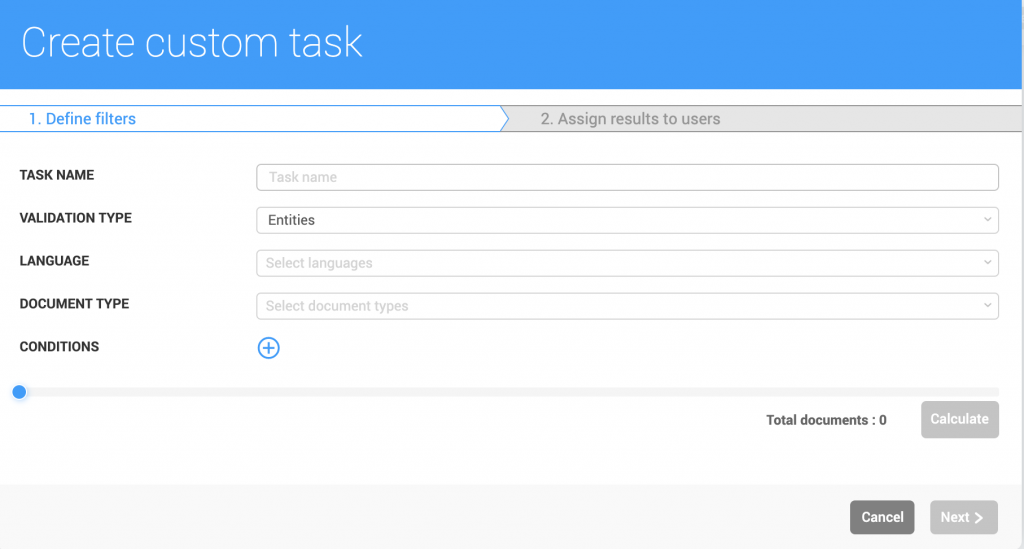
- Filters throughout the application will indicate through a number next to the filter icon how many filters are active
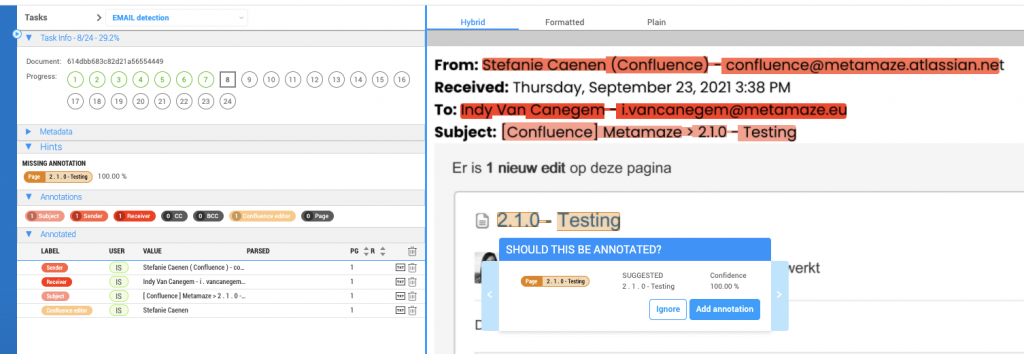
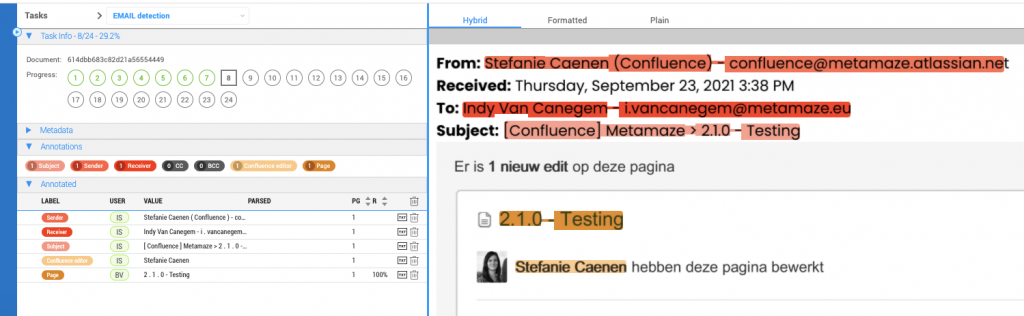
- When opening a document for which entity extraction is still in progress, you will clearly see a progress indicator on the screen
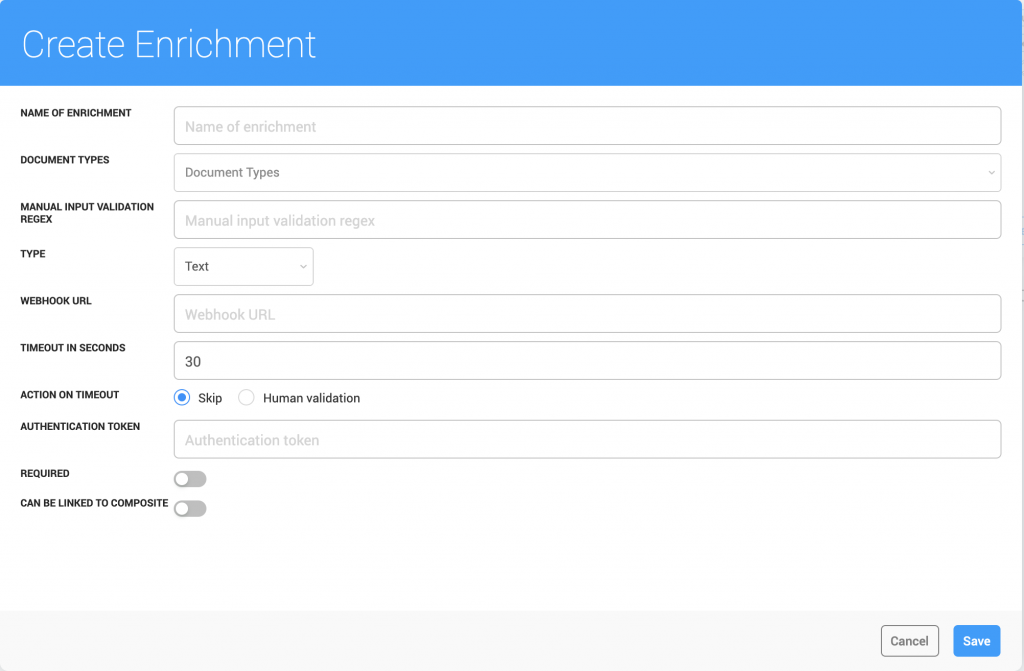
- When creating new users in Metamaze, automatic emails will be generated for the user to set their own passwords
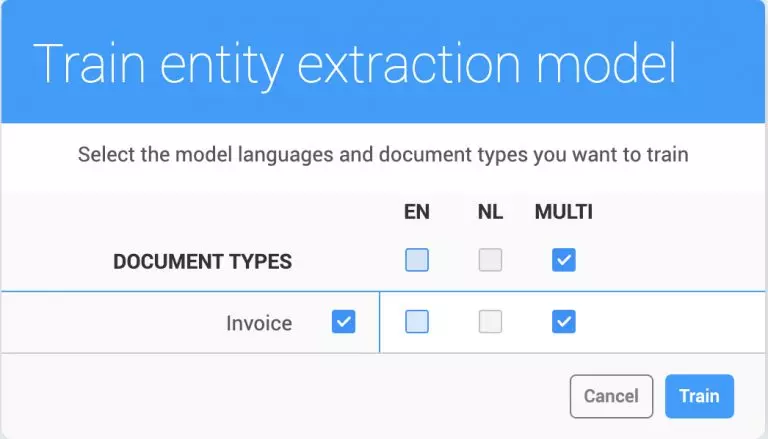
- Models will now be deprecated after 6 months when they haven’t been used to make predictions.
- Jump from upload to upload when in the document view without the need to go back to the overview of uploads
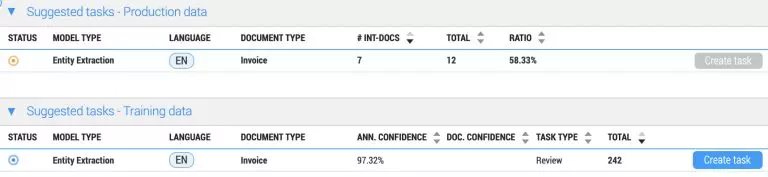
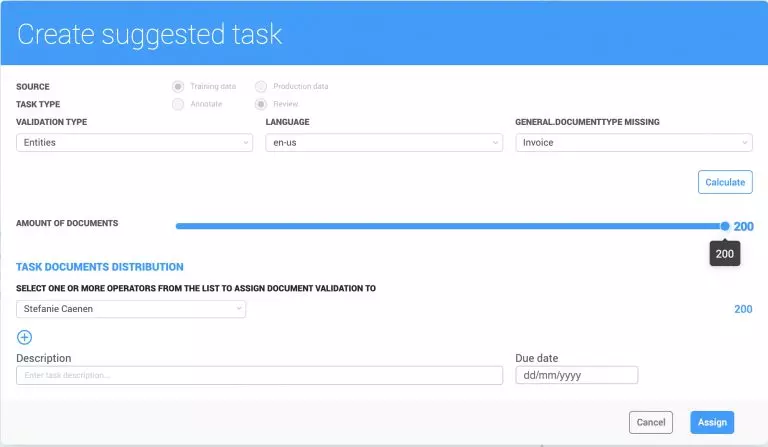
- Training speed for certain documents has been increased by ignoring pages without annotations
Our entire product team is very enthusiastic about these improvements. If you have any problems, questions or need advise, don’t hesitate to reach out to us via support@metamaze.eu.
CONTACT US
Questions or problems?
Don’t hesitate to reach out to support@metamaze.eu