Banks moving from front-end to back-end transformation.
- By Jo Cijnsmans
- | March 8, 2022
Banks have been under pressure for quite some time now. Digital transformation projects have become top-priorities for finance enterprises. But these efforts have been hugely centred around improving customer experience from a front-end point of view. Huge investments have been made on the top of the tech stack: the front end. A lot of beautiful experience have been launched in the form of portals, onboarding, experiences, mobile apps, …
However: the back office is an integral part of the larger customer experience and should not be overlooked. 60% of customer dissatisfaction originates in the back office. The biggest part of customer centre contact points is the result of execution issues in the back office. So what’s going on?
Banks and their manual processes
Behind the slick appearances of fancy mobile banking apps, banks’ operations are riddled with manual steps and inaccessible data. Bank’s current back offices are overly reliant on paper and manual processes.
Of course, current processes originate from the long-standing human-centric procedures for a big part. Compliance has resulted in a lot of manual reviews and processing.
But at Metamaze, we believe that processing documents should not require a lot of manual work. So why does it?
Challenge 1: 80% of your data is trapped below the surface
Why do all the deposit slips, credit reports, competitive analyses, loan agreement forms, stock market reports, letters of credit, bank pre-advice, … need processing?
One word: information. Or in modern lingo: data.

Unless it’s blank, a document has data on it.
(even then, one can argue no data is also data)
Data is the new oil (yeah we know, you’ve heard this before).
And interpreting data used to require a lot of work because of the format it comes in: structured and unstructured documents.
Structured documents are easy peasy lemon squeezy. It’s organized in a predictable, orderly pattern. Think of spreadsheets. Structured documents are usually composed of numbers or values that make it relatively easy for OCR (optical character recognition) to extract, interpret and classify information.
But… the hurdle comes when we’re talking about unstructured documents. Highly unsystematized, more unpredictable forms due to the variety of formats: email, chat, sensor data, IoT, video files, …
So extracting data from unstructured documents requires effort and by necessity: it has largely become a human job, albeit a tedious one.
In recent years, banks have been investing in technology to automate and streamline processes. But 87% of these initiatives fail.
Eighty-seven per cent!! 🤯
These technologies are only suited for structured documents, which is only 20% of the information large banks handle.
So what happens with the other 80%? Bank statements, pay stubs, standard settlement instructions, … these all still require humans to manually review, sort and understand data that is largely inaccessible.
Did you know that an average mortgage application goes through 35 manual handoffs before completion?
Challenge 2: the variability of documents is endless
Current approaches (often including in-house solutions) all fail to move the needle for one simple reason: the variability of documents is nearly endless. Even worse: the variability creates more manual work.
Why? Because a lot of automation solutions can’t handle the variability. If you code a template-based solution to extract data from a payment slip with lay-out A, it will not be able to extract data from the same document in lay-out B.
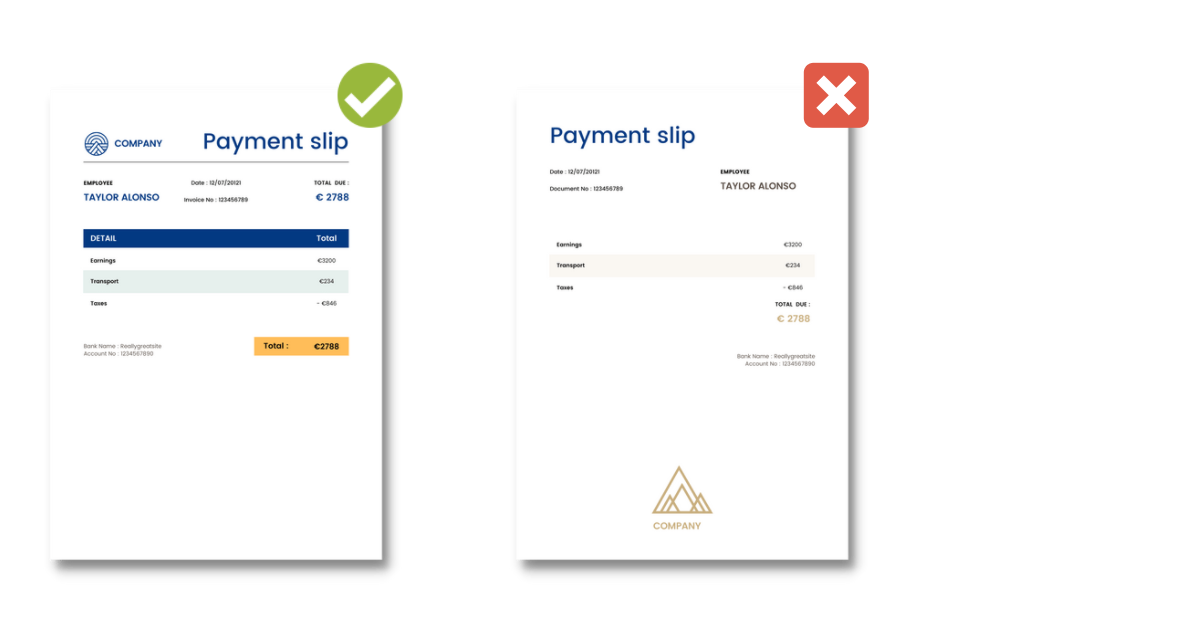
Challenge 3: narrow use cases
When identifying innovation trajectories, banks are often focused on specific use cases. But it’s not enough to identify one clunky process and build/buy a tool for it.
You will find accurate solutions, for sure. But with a very narrow use case. You don’t want to build a scattered IT landscape resulting in a patchwork of solutions.
So considering these challenges, it’s somehow understandable that manual processes are still common place in banks. However, automation is key to survival in this hyper-competitive market and increasing customer and employee satisfaction levels. And that’s where Intelligent Document Processing comes in.
Intelligent Document Processing: what? 🤔
Intelligent Document Processing –let’s call it IDP (time=money, right?)- is a technology-based on artificial intelligence and OCR that allows banks –like yours- to automate the data extraction from complex, unstructured documents and convert them into usable data.
To keep things simple: an IDP-solution uses different technologies in the process to extract, interpret, categorize relevant data.
Imagine you want to automate loan application processes
A big part of the workflow is checking and validating a huge number of documents. Before a loan can be accepted, banks need to establish a clear insight in the financials of a family or company. That means validating official documents (salary slips, contract, application forms, …).
Banks’ talented loan experts have to perform tasks that are not particularly challenging. Does this sound like a nice job to you?

Intelligent Document Processing helps you with that. You input the document into Metamaze and it will do the following for you:
- Pre-processing: optimize document for further processing: converting from image to text, cleaning up the document, …
- Document classification: ordening document pages, recognizing document type, detecting the language, …
- Extract information: whatever you want (dates, places, payments, names, …)
- Object recognition: identify if signatures are placed correctly, handwriting, …
- Data enrichments: finding BIC-codes for a given IBAN number, finding company names for VAT numbers, ...
- Business rules: checking if the loan fee is not more than 2/3rds of the net salary, are there enough signatures?
And then this information is outputted to your systems again.

For sure, the reality is a bit more complex than this.
By this moment you’re probably curious to see more?
In the next blogposts, we’re going to take a deeper dive into specific use cases for the finance industry. Sign up for our finance newsletter to get them directly into your mailbox. ⬇️
Discover how Axa automates their loan application process
Thanks to Intelligent Document Processing, AXA manages to process the same amount of loan application documents with less than 50% of the time and effort.



