Retrain your models fast with incremental learning
- By Jo Cijnsmans
- | June 30, 2022
In our previous blogpost, we talked about the importance of good data and annotations to train the model. Our data-centric AI approach is central to the development of our product. That’s why our Machine Learning team has been working hard on implementing incremental learning methods in Metamaze. In this blogpost, we’ll give you some insights on how that improves and accelerates the training of your solution.
From traditional machine learning to incremental learning.
If you want to implement an Intelligent Document Processing solution, you need trained Artificial Intelligence models that are capable of automatically recognising the information you need from your documents. In order to train those models, annotated data is needed. We refer you to our previous blogpost to learn how we tackle data input to train the initial models.
It is often assumed that a “good” training set in a domain is available a priori. The training set is so “good” that it contains all necessary knowledge, and once learned, it can be applied to any new examples in the domain. Unfortunately, many real-world applications do not match this ideal case. Trained models need to be updated every once in a while, to learn new cases that differ significantly from the already learned ones. This can be achieved by re-training the models with the old and the new data. While the training dataset grows, the training time increases, and at Metamaze we believe this is not sustainable. That’s where incremental learning comes in.
What is incremental learning?
Incremental learning is a method within the machine learning domain that allows models to continuously learn and extend the existing model’s knowledge, by adjusting what has been learned previously based on new examples.
Why we integrated incremental learning into Metamaze.
With our human-in-the-loop automation flow, the users are asked for validation of predictions in case the model is not sure enough or misses an important piece of information. All manual corrections and confirmations on the production data are added to the training dataset, to further improve the model. Once these corrections are learned by the model, the same type of errors cease to occur in the automated production flow.
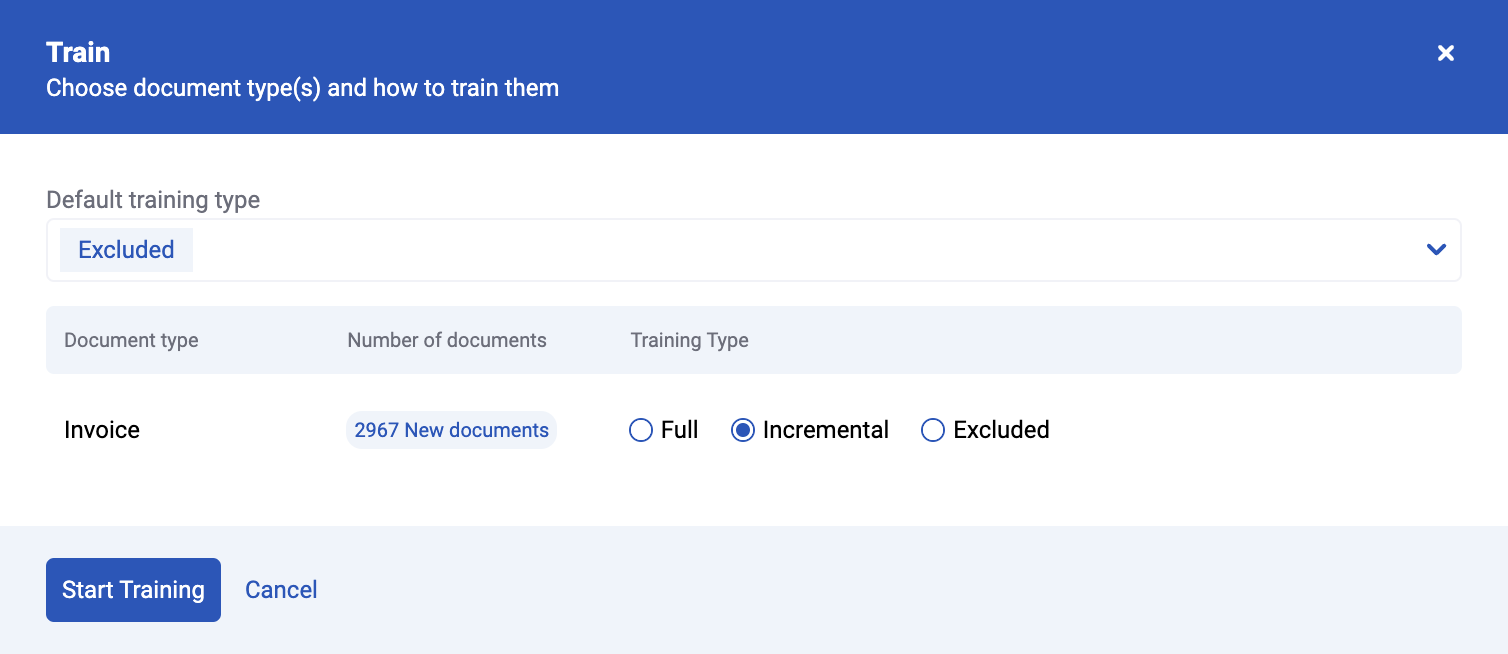
In order to incorporate the new data in the AI models, the users need to trigger a training. They can choose between a Full or an Incremental training. This means they choose between training a model from scratch with all the available training data, both the data the model already knows and the new data, or updating an existing model with only the data that the model hasn’t learned yet.
So basically,you can continue training a model starting where you left off. This has of course some advantages.
Drastically shorter training time
Training a model from scratch can take several hours, or even days, depending on the size of the dataset. This means that the users have to wait quite a long time before reaping the benefits of all their manual corrections. With an incremental training, the already trained model is simply updated with only those data samples it previously couldn’t process automatically. These trainings are much faster, given that the datasets are small and the model already knows a lot about the documents to be learned, it simply needs to update its knowledge on some details.
Train new models faster by adding new entities
Another advantage is that you can add new entities. For example: if you have a model that recognizes name and invoice number, you can use the same model as a start to train a model that recognizes the name, invoice number and invoice date, without having to start all over again.
This basically means that you can “recycle” models in other projects. Of course, the biggest advantage is that the annotation effort is much lower: name and invoice numbers don’t need to get annotated anymore because the model can already recognize them. Only invoice dates will need to be annotated.
This reduces a lot of valuable human effort.
CONTACT US
Book a demo today
Curious how Metamaze works and what it can mean for your enterprise?