3 reasons to replace your legacy OCR solution
- By Jo Cijnsmans
- | August 30, 2021
The root of Optical Character Recognition (OCR) technology dates back to the first world war, when E. Goldberg invented a machine that could read characters and transform them into telegraph code. Since the 70s OCR is capable to interpret text printed almost any font.
Later on, in the early 2000s, OCR became available as a cloud-based service. You may already feel it yourself, but OCR technology is not really something new. It is a necessary link in any document processing project, but only involves the traditional transformation of a character-filled image into machine-readable text.
Traditional players in this OCR market have been looking for solutions for the past twenty years to convert their OCR output into a business-useable data format. In 90% of the cases this meant searching texts by means of keyword/keyvalue matching or hard-coded templates.
However, in recent years these non-AI-based techniques have become completely obsolete, as a result of which such solutions are no longer up-to-date in terms of both performance and maintenance. In addition, we see in the market that large tech vendors (Google, Amazon,…) are far ahead in terms of accuracy compared to the traditional OCR parties.
This blog gives 3 clear reasons why the choice for a traditional OCR player might have made sense 20 years ago, but today is unjustifiable compared to an intelligent document processing alternative.
Accuracy
Within a document processing or automation project there are different ways and moments to measure accuracy. The first step within such a project is the OCR step in which an image (eg scan) is converted into text. So here you can measure accuracy for the first time on the basis of the number of characters (letters, numbers,..) that are correctly read and converted. For example, in the past bad OCR engines had trouble distinguishing between a ‘1’ and a ‘7’ or the letter ‘o’ and number ‘0’.
Today, OCR technology has progressed further and such errors occur less and less. Limitations are mainly still in cursive handwritten text and documents with exceptionally low legibility.
The technological evolution of the big tech players (Amazon, Google,…) has ensured that traditional OCR/scanning organizations score much lower in accuracy than these solutions.
Recent benchmarks show that these are significant differences between 15-20% character level accuracy depending on the engine.
Regardless of whether you use templates or AI, this is in any case a very bad basis for building an automation.
Legacy software
As mentioned in the introduction, traditional OCR software has been around for a long time. Many companies have often been using a certain OCR (+ template) software for years, the purchase of which often dates back to a few CIOs ago.
The software is often outdated, built in old technology but strongly entwined with the business processes.
Everyone knows this is not the optimal way but keeps using it because of sunk costs and habit. In addition to sub-optimal accuracy, there are a few other ways in which legacy software harms your organization:
- Old software often also means an archaic interface that no end user likes to work with. Often 20 years ago on these old OCR engines a tangle of complex modules/pop-ups was built that dates from the windows 98 era. New, Intelligent Document Processing SaaS platforms are built in the latest technologies, making the user experience much better and simpler.
- In addition to end users, the developers and admins within your organization should also be taken into account. Configuring and integrating with a traditional OCR solution is hell for these people. Evans Data Corp estimates that the global GDP loss from developer time spent on bad code amounts up to 85 billion. You’re throwing money down the drain when maintaining legacy software.This is in stark contrast to an IDP solution, such as Metamaze, where configuration and integration is just a few clicks and the integration of a REST api.
The impact of bad code:
- 41.1 average hours of developer workweek
- 17.3 average hours spent by developers on bad code, debugging, ...
- 13.5 average hours spent on technical debt
- 3.8 average hours spent on bad code
- 9.25% productivity loss from bad code
- $85 billon global GDP loss from developer time spent on bad code anually
Traditional OCR and template systems are not self-learning
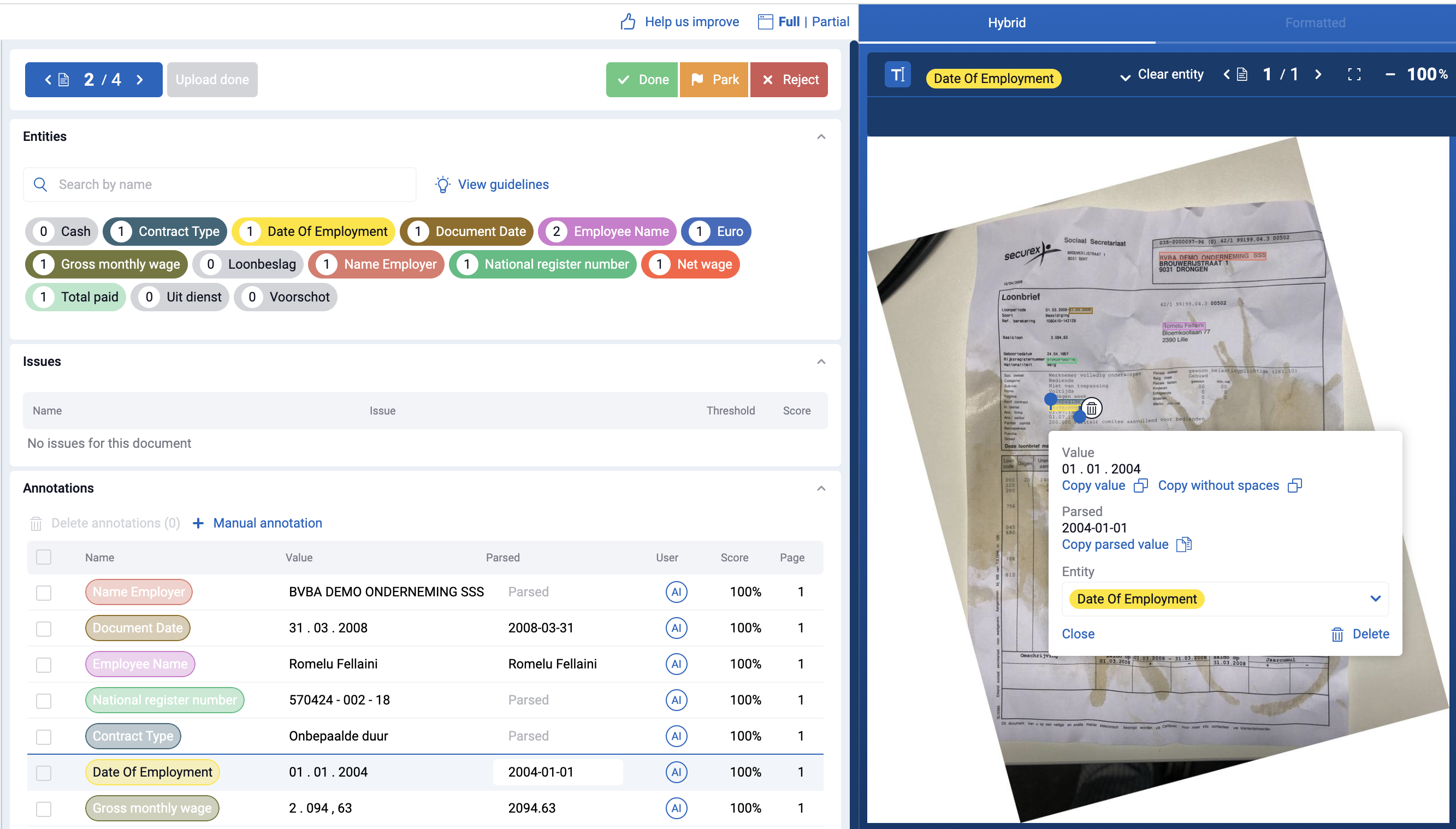
Traditional (and even some more recent) document processing solutions do not have the capability to actually learn from user feedback. More often than not, organizations who rely on these types of systems are forced to either spend development days creating and maintaining a set of templates (per vendor, customer, partner,…) or pay their software vendor large amounts of consulting fees to do it for them. Whenever the structure of the documents you receive changes (eg. A total amount is now 1 line lower than before) your system is unable to interpret the document and your automation fails. A summary of such a situation can be found in the image below (left side, OCR + Template).
| OCR + template | OCR + AI |
|---|---|
| Create initial templates (hard-coding, developer) | Build initial model (Annotation, business user) |
| "Automate" only for known, structured templates | Automate for all (un)structured templates |
| Add new templates for new suppliers/customers/... Maintain templates from current suppliers/customers/... (hard-coding, developer) | Correct the model when confidence is below threshold (a few clicks, business user) |
| Performance degrades over time because: amount of new templates > time spent on maintaining templates | Performance improves over time because: corrections are automatically used to improve the algorithm |
Today, more and more systems allow some form of user feedback. Traditional OCR (+ template) solutions sometimes provide old-fashioned and complex validation screens. The user can give feedback here, but does not get insight into what happens with his feedback. The complete “retraining” takes place behind the scenes at the software provider, so it is not certain how and whether these corrections are actually used to improve performance. A common complaint with such software is that hours are spent on validation, while the system is not improved and therefore does not seem to learn.
However, a really modern and self-learning application allows the user to easily make corrections, which are actually used to make the model smarter. This is only possible when a system is built from AI components, where traditional OCR suppliers use AI mainly as a nice marketing term. Metamaze attaches great importance to retraining and accuracy and enables the customer to manage his own models, so that his performance can be increased almost daily.

Conclusion
It is almost a 100 years after Goldbergs invention and it is time for large organizations to move from traditional OCR (+ hard-coding) towards a more intelligent way of interpreting and processing documents. The progress of large tech vendors in terms of OCR, the introduction of AI into this field and the rise of applications built in more recent technologies are taking the document processing market by storm. Traditional, incumbent OCR firms are turning towards AI as a marketing gimmick but the lack of a transparent, performant (re)training pipeline indicates the presence of legacy technology which leads to high maintenance costs and poor performance for your organisation.
The choice for a traditional OCR player might have made sense 20 years ago, but today is unjustifiable compared to an intelligent document processing alternative. We, at Metamaze, are happy to bring your document processing into the 21st century with our state-of-the-art platform.
Request a Metamaze demo
Learn how Metamaze can help you automate any document and email in your organization. Book a demo with one of our experts and we’ll give you a quick tour of our product.
