
Intro
Documents. Gargantuan amounts of documents tsunami businesses every day. Processing is often still done by actual humans. Reading them, interpreting them, taking actions and obediently re-typing the information into other systems.
This boring and non-value adding work takes up an increasing amount of time in a world where the need to trace decisions and documentation keeps rising. Self-service web forms help with reducing the workload, but too many jobs still contain a significant amount of simple document and information processing.

Progress in Artificial Intelligence is fast and often with spikes, but still we can make some reasonable forecast of what intelligent systems can do now, and where technology is going.
Definitely from a human perspective, we can tell where we are and where we want to go in the future when it comes to reducing – or fully automating – data entry, data extraction and other document processing tasks. To give structure to these thoughts and align on terminology, I’d like to introduce you The 5 levels of intelligent document processing.
Intelligent Document Processing (IDP) is an application of computer science that uses Artificial Intelligence and software robots to automatically interpret, recognise, filter, clean, extract information and make decisions from structured or unstructured, paper or digital documents.
Definition Intelligent Document Processing
Level 0 – manual processing with no automation
At the time of writing, a lot of document processing workflows are still handled completely manually. In such a process, every incoming document has to be read, recognized, interpreted and in a lot of cases entered into a different system manually.
Depending on your process, this could range from a couple of documents per day to a couple of thousands of document per day, with human effort ranging from a couple of minutes to a 10-people team working full-time on processing all these documents.

Level 1 – simple template-based extraction
A Level 1 IDP system works by explicitly capturing and coding knowledge of the documents. This can be by defining fixed layouts and graphical templates for extracting certain fields. Or by extensively using regular expressions, fuzzy matching and keyword based extraction.
Any change in the template or layout of a document, or any new type of document requires programming or customisation effort to get the solution to work again. From a business case perspective, this is typically only achievable for document types with a very large volume (100k+ a year) and at the same time contain little to no variation per document. Examples could include onboarding forms with a fixed company template, or forms that are generated automatically from a template.

Level 2 – training-based document processing relying heavily on annotation and training based on a lot of documents
Level 2 IDP systems work by learning from lots of data using machine learning and artificial intelligence models.
These systems can handle complex documents with a lot of variation, but require thousands of examples to accurately predict and extract. In a controlled setting with high-quality scans, they are fairly robust for slightly changed layouts, typo’s, scanning artefacts, … Even for new layouts the model can often make fairly good predictions, as long as they are document types for which a model already exists.
Human annotation – mostly from scratch – is needed for low-confidence documents or a significantly new layout. Typically, multiple examples of the same layout and a re-training the model are needed to close the feedback loop in which the model learns to recognise new document types.
Human effort is still required for training and annotation of the initial models and for improving recognition rates over time.
Level 3 – autonomous extraction relying on few-shot training 👈 state of the art is here
A level 3 system works out of the box for common document types, but still requires some human annotation effort for new document types.
For popular document types, typically no set-up is needed. If the domain is very different, by correcting a handful of documents during the first weeks of production, the model achieves target accuracy. Layouts that are significantly different than previously seen still need some human validation for correcting or validating the predictions. The model adapts after a re-training on that annotated data and is robust to annotation mistakes up to a certain level.
Validation rules are set manually to ensure data consistency.
For custom document types, some initial annotation is still needed to get started. After annotating a handful of documents from scratch, the model searches through the documents to find outliers and asks for validation or proposes corrections (active learning with predictions). The human involvement for training custom models is reduced to correcting ambiguous situations, where no annotation from scratch is needed besides the first dozen documents for a new document type.
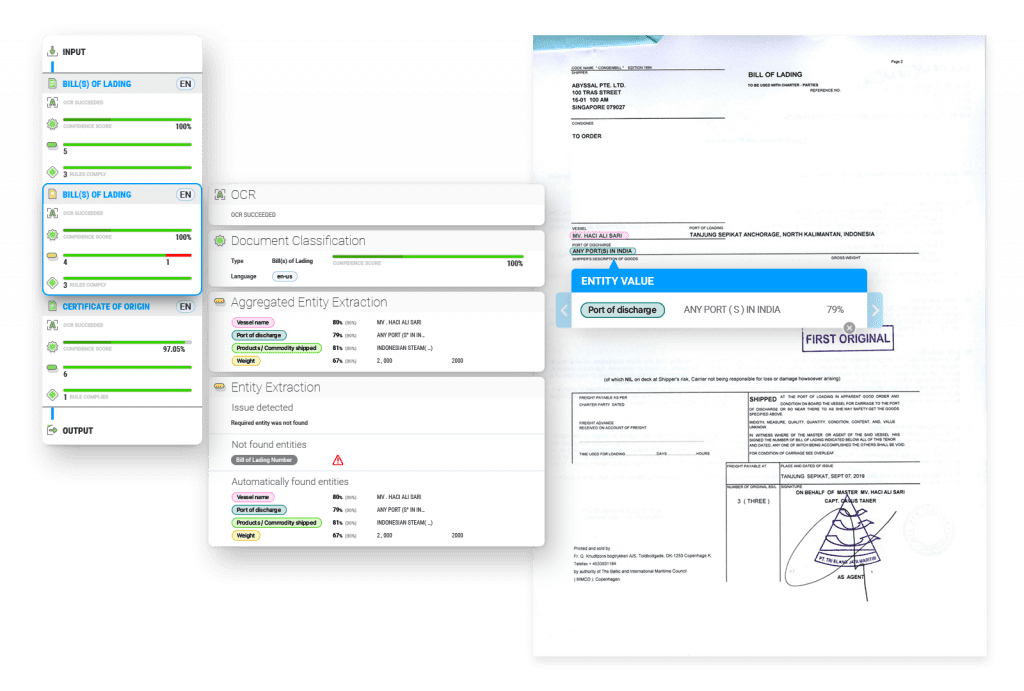
Level 4 – zero-shot autonomous extraction with rare exception handling
Level 4 IDP systems are systems that work for all document types out-of-the-box. They learn from a minimal amount of exceptions from the start even for new document types. Zero-shot models are the standard: these models give useful predictions from the start for common entities, even if it is a new document type.
For common document types, exceptions are very rare. For new document types, simple fields like document date, subject, names, organisations, addresses and tables are automatically recognized. If common fields have multiple roles, the model learns to split them after correcting a couple of documents. For new document types, after correcting only a handful of documents, the models knows enough to process all automatically.
The model learns from new examples through continuous training and will never ask similar validations twice. Re-training happens in real-time and completes in a matter of seconds, with no need for explicitly triggering trainings or waiting for scheduled trainings to complete.
The exception flow itself is mostly automated, with the model rejecting bad documents with an appropriate failure code automatically.
Human validation for incoming data is only needed for ambiguous and new situations that are typically based on user error, with the models providing detailed feedback to the end user on what might be wrong and missing.
ISSUE: The currency values and percentage values of this marriage contract don’t add up: it mentions 100.000 EUR (45%) for Bill and 120.000 EUR (55%) for Melinda.
Do you want me to
a) take the numerical values and keep the percentages
b) take the numerical values and override the percentages
c) return the document to the originator with a message asking for explanation
In Level 4 systems, the models learn to recognise relationships between different data fields. For example, the model learns that amount with VAT is always higher than amount without VAT without the need to explicitly code this information. The process also knows how to link multiple instances and how to recognise duplicate information, for example that Bill Riker and William K. Riker are two references to the same individual.
Level 5 – fully autonomous document processing
For a fully autonomous level 5 IDP system, the A.I. models work out of the box for any document type in any language. The model interprets and processes documents fully automatically, by making decisions based on language models and word knowledge.
New document types get clustered and are assigned a generated, readable label based on their title and content. Even for new document types, entities are parsed automatically based on key-value extraction and interpretation of the document and other documents in the same set. For example, if the model would never have seen a restaurant menu, it will still be able to infer that a dish has a category, a name, contains ingredients and has a price that are all belong together.
The model learns relationships not only within a document, but also across document types, recognising e.g. a serial number as a “device serial number” because it was also mentioned in a different document type “device sheet” as the serial number. Edge cases like printed text that is stricken through by pen and manually corrected are handled without the need For validation.
A level 5 IDP system selects the appropriate output action, which includes asking for more data, taking decisions or transforming and entering data into a target output system.
While they still happen, mispredictions are so rare that they only appear in increasingly exceptional circumstances. For the majority of users, the IDP models “just work” from the start onwards without any issues. Every misprediction is treated much like a bug would be in normal software, with a detailed analysis of the edge case needed by an engineer to figure out what to improve.
Writing this in 2021, I believe nobody can fully understand and predict if we will ever get to a fully autonomous level 5 document processing system, but we can at least try to get close !

Conclusion
Us humans should not be doing boring repetitive work involving simple or complex document processing. I am looking forward to further harvesting the benefits of exponentially improving technology. Applied research in Artificial Intelligence improves all of our lives and lifts us to new levels of productivity and self-actualisation.
This post was inspired by the 5 levels of autonomous driving and the 5 levels of conversational AI by Alan Nichol.