More data is better
“More data is better” says the proverb. But the actual situation is a bit more nuanced. Namely: the amount of information a document adds to the accuracy of the model is not the same.
Some documents are already perfectly recognised by the model, so the model would not learn anything from annotating and adding that document to the training set. So more data is not necessarily better.
Quality > Quantity
Other documents are very rare, and provide valuable examples for the model to learn from.
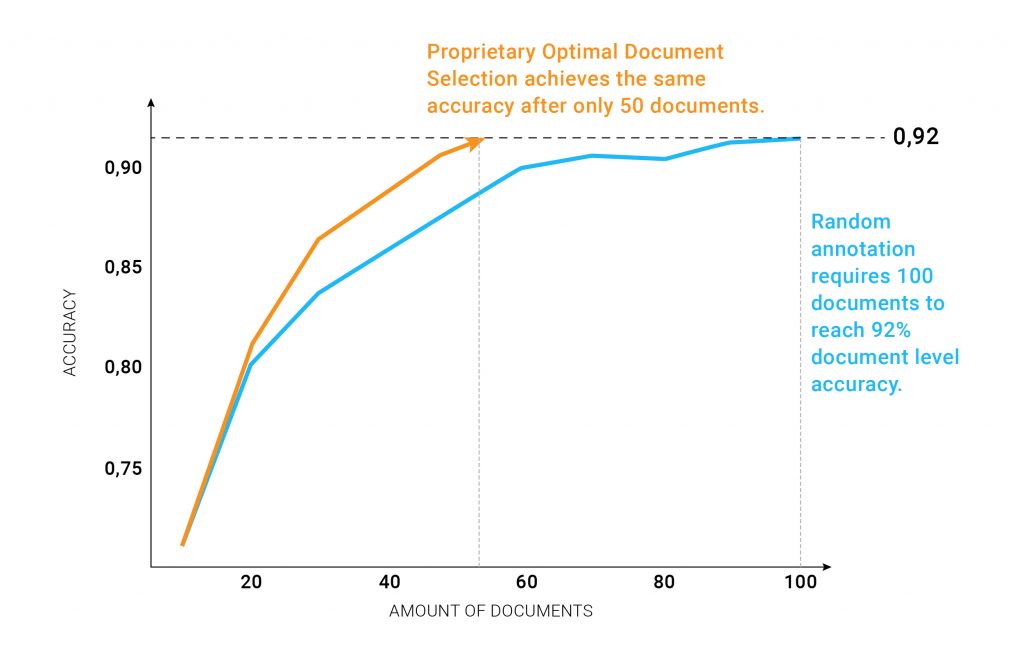
Optimal Document Selection Strategy
By using the Metamaze Optimal Document Selection Strategy, you are automatically prompted to only annotate exactly those documents that will help you improve the model the fastest. In the end, you have reached the same high level accuracy as before, but by annotating only 50% of the original documents, drastically cutting short the cost and time it takes to go to production.
Suggested Annotation Task
This will be available within the Metamaze Platform in the tasks module as a “Suggested Annotation Task”
The end result: twice as a fast
By using the Suggested Annotation Task feature that enables an Optimal Document Selection Strategy, you’ll end up with same model accuracy, but twice as fast!
TECHNICAL DETAILS
Predictions and confidence scores
When a training of a model completes, predictions are then made on all un-labeled documents that are present in the training module. Furthermore, each document gets a confidence score indicating how “confident” the model is about this document.
Low confidence scores are selected
For types of documents that the model knows well, the confidence scores will be high, but for the types of documents that were not present frequently enough in the training data, the model will emit low confidence scores. Documents with love confidence scores are then automatically selected to annotate next.
Confidence score metrics
As a prediction confidence score for a document, you can use metrics like
- Number of required entities extracted
- Number of parsing rules failed after extraction
- Lowest Token Probability takes the word-level confidence for the predictions and takes the minimum certainty per word.
- Mismatch-first farthest-traversal: The primary selection criteria is the prediction mismatch between the current model and nearest-neighbour prediction. It targets on wrongly predicted data points of existing annotated data. The second selection criterium is the distance to previously selected data, the farthest first. It aims at optimising the diversity of selected data. In both steps, you use cosine similarity in the layout-aware document embedding space as the distance metric.
A Practical example
Let’s look at a practical example: for training a model that extracts relevant information from invoices, you will upload 2000 invoices of a multitude of suppliers. You will label an initial random set of 100 invoices and train a model. Imagine that this randomly selected set contains a lot of invoices for supplier A, a decent amount for supplier B, barely any for supplier C and none for supplier D.
When training completes, predictions are made on the remaining 1900 invoices. The model will be able to make very confident predictions on invoices for supplier A, slightly less confident for supplier B and not confident at all for supplier C. Surprisingly, the model makes very confident predictions for supplier D, even though no data was seen for this supplier. Turns out their invoices are very similar to the invoices of supplier A, hence enough information about these invoices is already present in the model. A suggested task will be created for you to label more data of supplier B and C.
After labeling an additional 100 suggested documents, you retrain the model and predictions are made on the remaining 1800 documents. Again, a suggested labeling task will be created based on the confidence of the model. This process is iterated until a satisfactory accuracy is reached.
In Conclusion
Ever since Metamaze release 1.7, our users are able to use the Suggested Annotation Task feature of Metamaze, which ultimately results in the same model accuracy but twice as fast.