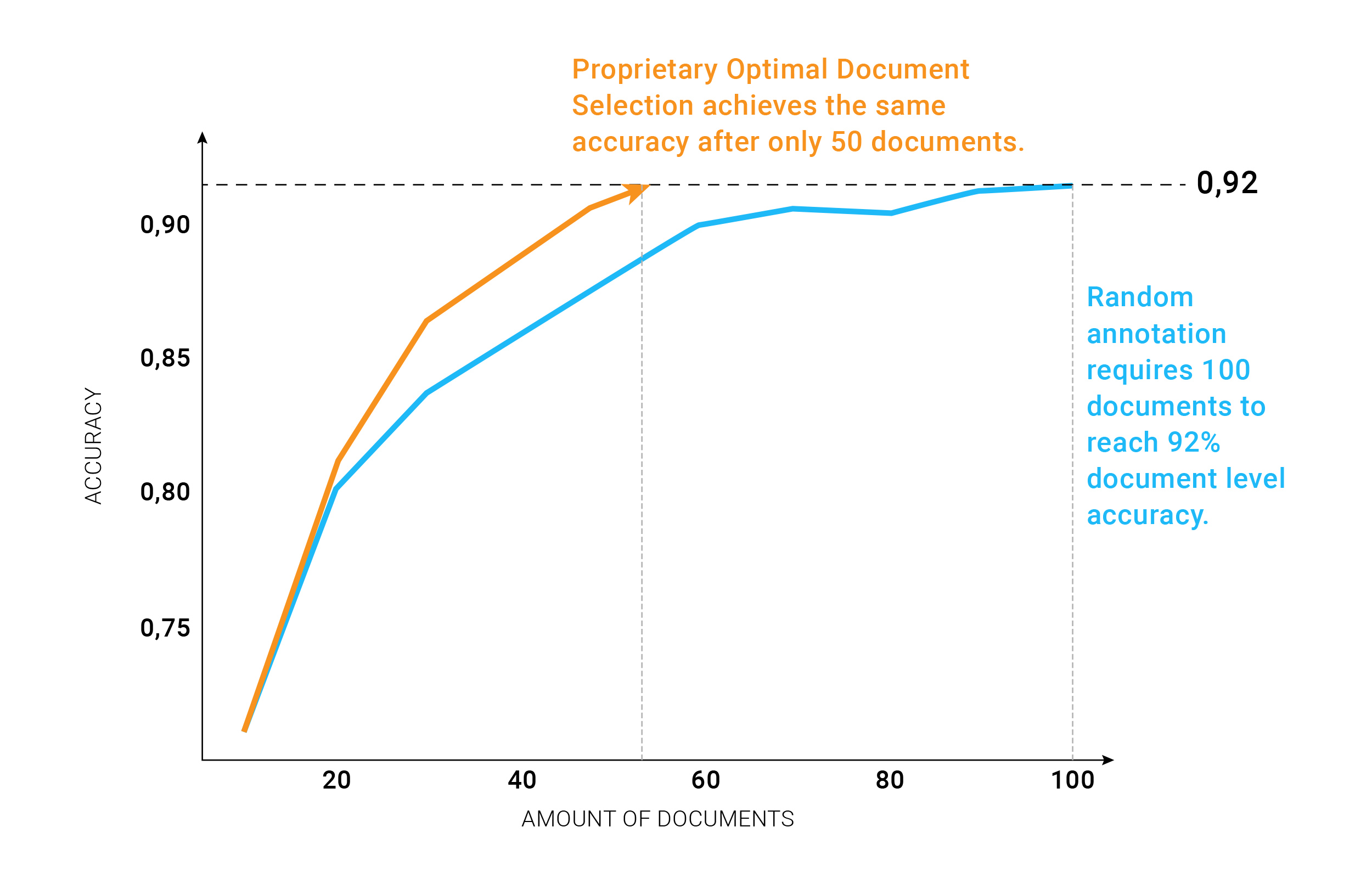
“You can think of these models as a recipe. Most recipes are good. If you follow them, you’ll get a delicious meal. But if you make the recipe with rotten ingredients, chances are big you might not enjoy it. The same goes with AI models. If you insert bad data to train it, the outcome might not be what you expected. On the other hand, cooking with delicious, carefully grown and selected high-quality ingredients can push a good dish to savory masterpiece.”