Why the quality of annotation is more important than the quantity.
- By Jos Polfliet
- | March 24, 2021
Any machine learning model can only be as good as the training data that was used. If you don’t annotate all occurrences of a field, the model will be confused when it needs to extract this field (or not) and give low confidence scores.
Think of it as a teacher (you) that teaches his students (the neural network extraction model) confusing, contradicting or incomplete information. The student will never get good results. This is true for any deep learning model: regardless of whether you are teaching a strong A.I. to play chess using reinforcement learning by rewarding bad moves or using machine learning algorithms for document intelligence.
Bad teacher = bad students
Bad data = bad model
In the world of AI technology, annotators that don’t make mistakes are science fiction
Annotation is hard and human annotators make mistakes all the time. Even highly educated, laser-focused engineers, accountants or sales reps filled with coffee make mistakes on any specific task. Some companies resort to having every document annotated independently and from scratch twice. That is a huge drain on your human capital! Even after using this so-called “four eyes principle”, often an error margin of 2% cannot be avoided. I repeat: annotation is hard and human annotators make mistakes all the time.
Depending on document type, after the initial annotation, as much as 35% of documents can still contain (small) mistakes. After a first full human validation, that number can go down to maybe 10% of documents.
In annotation, quality is more important than quantity
Strong A.I. starts with good QA engineers
Correctness of annotation is hard but crucial to getting good performance. Fixing annotation mistakes can easily lead to a 10-20% improvement of your model and is considerably less effort than annotating extra documents from scratch. In addition, adding new documents will not help the accuracy of the model if the existing documents still contain mistakes. You need to add about 5 times more annotated training data to your neural network to get a similar accuracy improvement compared to just fixing the original dataset. So, we always recommend correcting the existing data first before you add new data.
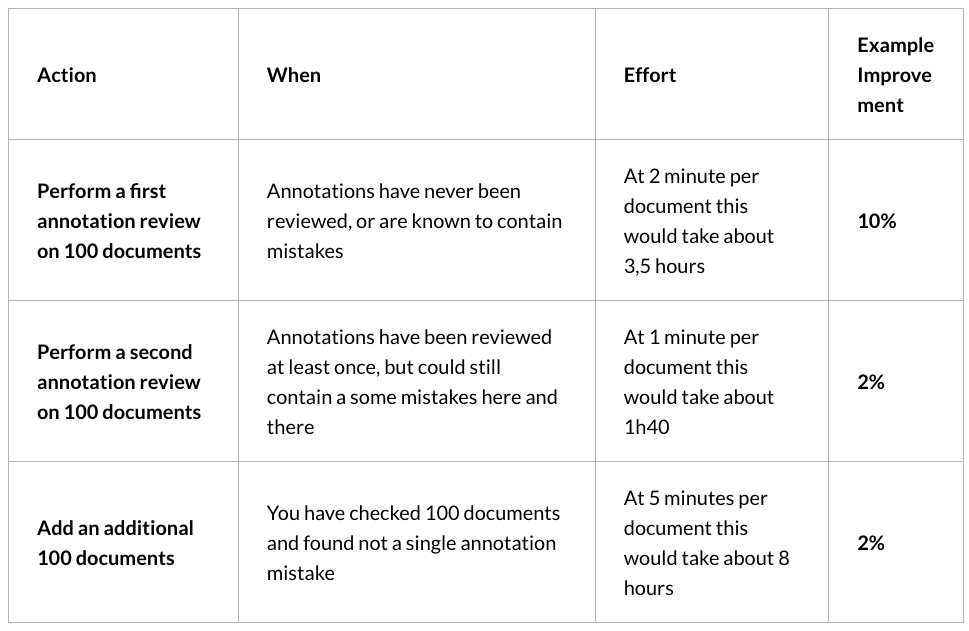
| Action | When | Effort | Example Improvement |
| Perform a first annotation review on 100 documents | Annotations have never been reviewed, or are known to contain mistakes | At 2 minute per document this would take about 3,5 hours | 10% |
| Perform a second annotation review on 100 documents | Annotations have been reviewed at least once, but could still contain a some mistakes here and there | At 1 minute per document this would take about 1h40 | 2% |
| Add an additional 100 documents | You have checked 100 documents and found not a single annotation mistake | At 5 minutes per document this would take about 8 hours | 2% |
Review annotation tasks
Review tasks are used to help correct mistakes. In Metamaze, review tasks are automatically suggested based on data that might be misannotated. Think of it as automated testing for annotations.
After the initial annotations of a certain document type, we recommend doing a QA task on all documents using the Custom QA tasks module.
When a certain document type or field is underperforming, you can also do a targeted, custom QA task focusing on specific entities, annotators, variations, …
The road to max efficiency
However, checking all data of a certain document type can be inefficient: a lot of documents will be (hopefully) fully correctly annotated, so you waste time going over all of them.
Therefore, we introduced the Suggested Review tasks in the Metamaze Platform, that use Artificial Intelligence and deep learning to select which documents need an extra review and which you can safely ignore. The next blog post will go more in-depth on how that works on a technical level.
CONTACT US
Book a demo today
Curious how Metamaze works and what it can mean for your enterprise?