
Whether you are automating internal processes, or want to incorporate intelligent document processing as part of your own software, you might be thinking:
Should I build my own custom intelligent document processing solution or work with a partner?
In software, it is not always as straightforward as when buying a car vs. building a car from scratch. It is more like writing custom spreadsheet software that matches your needs exactly. This blog posts aims to offer some perspective on which factors you should consider.
We have built Metamaze to be extendable and embeddedable into other software products so you can focus on creating your own products and benefiting from our years of expertise in the field for a vastly lower total cost compared to reinventing from scratch.
Requirements and scope creep
When working in a team that has talented Data Scientist, Machine Learning engineers and Full Stack Developers, building your own information extraction engine may seem perfectly feasible. Maybe you even did a proof of concept. Or have a working prototype.
Often, this would start with a POC set-up similar to this
- text based spaCy or transformers extraction pipeline that gets decent results
- a basic way of annotating data on the document
- integrating a cloud-based or open source OCR provider
While those first results are promising, moving from a POC like that to a mature pipeline is typically one or two orders of magnitude more effort.
Requirements
Suddenly, more requirements become important that were not part of the initial POC:
- user friendly annotation and validation modules incl. annotation queues, dividing effort, annotating on the document, shortcuts, patterns, auto-correcting annotations, …
- document management incl. filtering, searching, assigning metadata, tracing, …
- scalability and security
- image enhancements, rotating, removing blanks,… of PDF’s and scans for OCR
- Model management including automatic and stable re-training from feedback, deploying, evaluating, comparing and version control of all the models
- Dealing with edge cases like funky file formats, long documents, parsing of weird dates/numbers, aggregating predictions with different values and confidences, …
- Pre-trained multilingual and multi-modal models that use layout + text
- extracting line items or composite entities
Nice to haves
While often not strong requirements, some features are nice to haves and can cut integration time and ensure software is aligned to your expectations from the start.
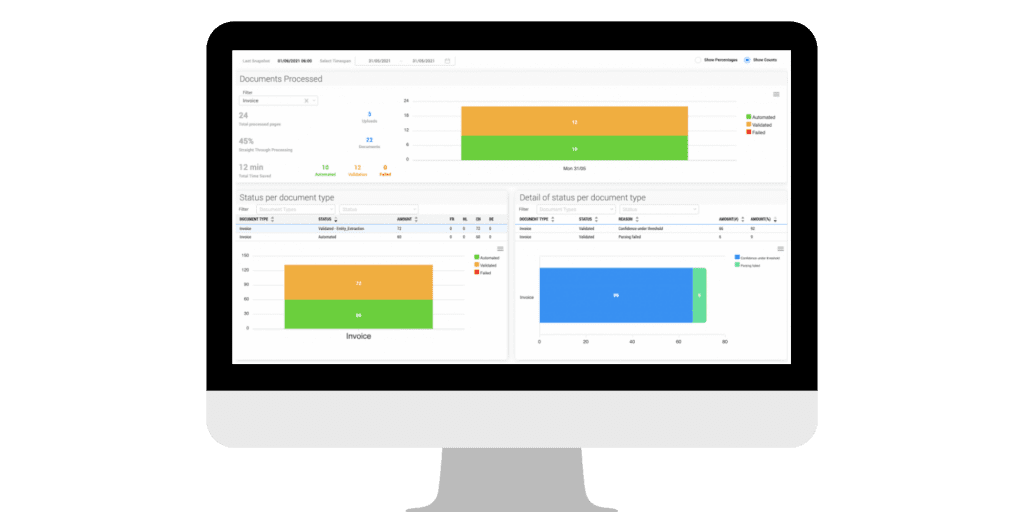
- Dashboards to track performance
- Layout-aware models boost accuracy by 3-20% compared to standard spaCy/transformers NER pipelines with 10% of the data.
- Role based access control and SSO
- Audit trails of all actions in the platform
- Access to experienced teams for annotation and implementation
- Other model types for splitting/merging pages, document type recognition, …
- Active learning selects which documents provide the best information to train the model on, decreasing annotation requirements by up to 75%.
- Misannotation detection helps detect wrong annotations.
- Tasks modules for improving data and assigning work
- Pretrained models for 25+ document types including invoices, purchase orders, bill of ladings, salary slips, ID cards, certificates of origins, annual reports, …
How to decide
You don’t decide to buy or build based on one criterium, but by taking into account many facets. Depending on your company, some of these will be less or more important in the decision:
| Factor | Build is better | Buy is better |
| Total cost of ownership | No recurring license fees | Don’t reinvent the wheel. Configuration and extension of existing platform has faster time to value and vastly lower initial costs. No scope creep, budget overruns, integration cost Maintenance, security, hosting costs, … are all included in the license fee and offer no unexpected effort or costs from your side |
| Capabilities | You can tailor make all capabilities exactly to your needs Your problem needs to fit the solution’s capabilities and extension possibilities. If not, the cost of customizing the product might be higher than building from scratch. | A lot of the functionality you need probably already exists, with integration points and plugins to foresee custom logic/models if needed More features available that are nice to haves |
| Maintainability | NA | Feature updates and bug fixes by provider Security updates by provider |
| Time to production | NA | Integrating an existing solution typically is faster than building from scratch |
| People and experience | Business and subject matter expertise | Experienced and dedicated team to help you that works together with your subject matter experts |
| Strategic Focus | Building your own capabilities might be strategic priority | Building your own capabilities might distract you from your own strengths, core capabilities and strategic focus |
| Intellectual property | Code is worth something and could be re-used for other purposes | Trained models are your IP Custom OEM/re-seller/escrow/license terms need to be agreed on |
| Data residency | Can be hosted where you want, including on premise | Is hosted by the provider in a SaaS model. On-premise or private cloud deployments typically require extra SLA’s and effort that make the difference in total cost of operating smaller. |
Common concerns and objections
Common objections to integrating Metamaze vs. building your own
- I need a custom model, custom pipeline or custom logic.
Custom logic can be integrated by using enrichments which support custom models, data validation, lookups, … Pipelines can be configured in the Metamaze UI. Since our mission is to support all intelligent document processing cases for any document type, if somehow our existing pipelines have shortcomings for your case we will gladly discuss with you how to extend them to support your needs.
- My self-trained spaCy/transformer models works fine, why spend the effort in moving to Metamaze?
After evaluating on many different document sets, we have to conclude that all models benefit from layout information, and our layout-aware model outperforms simple Transformer / BERT models by anywhere between 3 and 20% in F1-score. Nevertheless, we offer you the choice to train both from in the UI. - We want to integrate the validation UI in our own applications and in our own house style.
This is possible through embedding our open React components for annotating, or by embedding an iframe. Both support custom CSS. Please contact the Metamaze team to discuss what the best option would be for you. - We do not want recurrent license costs and want to host the solution on-premise.
Custom license models and deployments are possible on request. Please contact the Metamaze team to discuss options and requirements. - Security will never allow a SaaS tool
Metamaze is continuously vetted and our mature security policies are trusted by large banks, telecommunications and manufacturing companies. Metamaze will gladly answer your questions on why that makes sense. We are working on ISO27001 certification, which is expected by October 2021.
If on-premises or private cloud deployments are necessary, please contact the Metamaze team to discuss options.
- I don’t want vendor lock-in.
We commit to always providing access to your own data. We will export all your data in a common format like JSON upon request.
Conclusion
While both a buy and build decision have advantages, we see that in practice there are many hurdles for organizations to further develop a complete, high-performance IDP solution after a first POC.
We have spent thousands of days building Metamaze into a user-friendly platform that can be extended and customized were needed. We look forward to giving you access to that power. If you want to discuss, feel free to reach out directly at j.polfliet@metamaze.eu!